INTELLIGENZA ARTIFICIALE DOMANI GINO RONCAGLIA
Può essere davvero “creativa”? Ci sostituirà? Quelle domande difficili sull’Ia

Finora i computer e la rete erano stati strumenti prevalentemente “servili”. Oggi, questa situazione sembra cambiare radicalmente: per la prima volta svolgono compiti che siamo abituati a considerare “creativi”. Ma cos’è, esattamente, l’intelligenza artificiale generativa?
Nel giro di cinquant’anni, il mondo dell’informatica ha attraversato almeno tre grandi rivoluzioni: la prima, attorno alla metà degli anni ’80 del secolo scorso, con la nascita dei personal computer; la seconda, nel corso degli anni ’90 e a cavallo del nuovo millennio, con la nascita del World Wide Web e con la diffusione generalizzata di Internet; la terza, all’inizio degli anni ’10, con la diffusione degli smartphone e degli altri dispositivi mobili connessi alla rete. La quarta rivoluzione, ormai avviata, è quella dell’intelligenza artificiale.
Sarebbe interessante discutere se ciascuno di questi sviluppi possa essere annoverato fra quelle che Schumpeter definiva «innovazioni che fanno epoca»: quelle che trasformano in profondità tutti i dati della vita economica e provocano “onde lunghe” nei cicli di sviluppo. Se fosse così (e credo lo si possa argomentare), le nuove tecnologie dell’informazione e della comunicazione avrebbero provocato non solo cambiamenti di grande portata a livello sociale ed economico, ma un’accelerazione avvenuta attraverso scatti successivi, molto ravvicinati fra loro, ciascuno dei quali produce una riconfigurazione radicale nei meccanismi produttivi, lavorativi, comunicativi, culturali delle nostre società.
In ogni caso, come e forse ancor più delle prime tre rivoluzioni, quella rappresentata dall’intelligenza artificiale promette (o minaccia) di cambiare profondamente il mondo intorno a noi.

Il cambio di paradigma
Finora i computer e la rete erano stati strumenti prevalentemente “servili”, guidati dall’intelligenza umana: un programma di videoscrittura ci aiuta a scrivere, ma non crea testo al posto nostro; un programma di grafica aiuta a disegnare o a ritoccare una fotografia, ma non produce autonomamente immagini; la rete è uno straordinario strumento per la diffusione e condivisione di contenuti informativi, ma quei contenuti sono creati da noi, non dalla macchina.
Oggi, questa situazione sembra cambiare radicalmente: per la prima volta, i computer svolgono compiti che siamo abituati a considerare creativi. I sistemi di intelligenza artificiale generativa producono testi, immagini, suoni che non esistevano prima, e che sono diversi da quelli su cui sono stati addestrati: il corpus di addestramento influenza e indirizza il processo di generazione, ma questo processo non produce “copie”, produce oggetti informativi nuovi.
ChatGPT e i molti altri sistemi generativi nati negli ultimi anni traducono un articolo, scrivono o commentano una poesia, creano immagini quasi impossibili da distinguere da quelle prodotte da artisti umani, possono comporre (e non solo eseguire) un brano musicale. E possono eseguire autonomamente compiti anche assai complessi: alcuni potenzialmente utilissimi – AlphaFold, un sistema di Ia sviluppato dagli ingegneri di Google, permette di scoprire le strutture tridimensionali delle lunge e complesse catene di aminoacidi che costituiscono le proteine, svolgendo in pochi minuti un compito che prima richiedeva anni di lavoro –, altri potenzialmente assai pericolosi, come la guida di un missile o di un drone, o la creazione di nuove tipologie di agenti patogeni o di virus informatici.
Domande difficili
Ma cos’è, esattamente, l’intelligenza artificiale generativa? Come ha potuto raggiungere in pochi anni risultati così sbalorditivi? Può essere davvero “creativa”? Può, in prospettiva, raggiungere e superare (o addirittura sostituire) l’intelligenza umana? Che effetti avrà sul mercato del lavoro, o in settori come l’istruzione e la formazione? Può essere pericolosa, e in quali modi? Come possiamo essere sicuri che rispetti i nostri valori? E quali sono, esattamente, i valori che desideriamo veder rispettati, considerando che società umane diverse sembrano adottare sistemi valoriali almeno in parte diversi e in qualche caso anche conflittuali?
Alcune delle domande che ci poniamo davanti a questi sistemi, e di cui ho fornito solo qualche esempio, sono legate al desiderio di “capirli” meglio: capire quali sono i loro principi di funzionamento, quale è stata la loro evoluzione, cosa potrà succedere in futuro. Altre sono domande decisamente filosofiche, che richiedono una riflessione non solo sulla possibilità di costruire sistemi intelligenti, ma sulla natura stessa dell’intelligenza (a partire dall’intelligenza umana), o sul significato di concetti come quelli di intenzionalità, agentività, creatività, o, ancora, sui sistemi di valori che devono o dovrebbero guidare la nostra ricerca in questo settore.
Sono domande che hanno però tutte un elemento comune: per provare a rispondere in maniera sensata, e non solo per luoghi comuni, occorre sapere – almeno a grandi linee – di cosa stiamo parlando. E per sapere di cosa stiamo parlando, occorre approfondire. Sarebbe infatti non solo sbagliato ma potenzialmente assai fuorviante pensare di poter rispondere alle domande “difficili” senza prima capire un po’ meglio come funzionano i sistemi di intelligenza artificiale di oggi, molto diversi da quelli del passato.

Esperti in disaccordo
Purtroppo, in questo campo errori di comprensione e fraintendimenti non mancano, neanche fra gli specialisti. È così abbastanza comune sentir dire che l’Ia generativa fornisce le sue risposte “copiando” dal proprio corpus di addestramento – mentre, come si è già accennato, non è affatto così – o che l’Ia generativa è sostanzialmente stupida perché commette moltissimi errori: l’attribuzione o meno di intelligenza a sistemi di questo tipo dipende largamente da cosa intendiamo per “intelligenza”, e in molti casi può essere senz’altro problematica; ma se gli errori fossero di per sé un sintomo della mancanza di intelligenza, non dovremmo attribuire intelligenza neanche agli esseri umani, che purtroppo sbagliano assai spesso.
Peraltro, nel caso dell’Ia la possibilità di ricevere risposte sbagliate dipende in parte dal meccanismo stesso di generazione (su cui mi ripropongo di tornare in un prossimo articolo, dato che questo è il primo di una serie), ma dipende spesso anche da nostri errori: ad esempio dal fatto di non conoscere la differenza fra un sistema generativo e un motore di ricerca come Google, che non “genera” risposte nuove ma si limita a cercare pagine Web che contengano i termini sui cui la ricerca è stata svolta. Vero è che da qualche settimana Google stesso unisce, nel fornirci un risultato, i risultati di una ricerca tradizionale e una sintesi prodotta dall’Ia generativa. Ma siamo sempre in grado di capire la differenza, e di valutare l’affidabilità di queste due componenti della risposta e la loro relazione?
È bene infine ricordare che in molti casi, anche fra gli esperti, le risposte alle “domande difficili” sono tutt’altro che univoche; interrogati sul loro grado di accordo o disaccordo con l’idea che alcuni sistemi di Ia generativa “capiscano” il linguaggio, 480 ricercatori del settore si sono mostrati divisi in maniera quasi perfettamente uguale fra le quattro risposte possibili previste dall’indagine: accordo totale, accordo parziale, disaccordo parziale, disaccordo totale (se ne volete sapere di più o risalire ai dettagli dell’indagine potete consultare un articolo molto interessante di Melanie Mitchell, professoressa del Santa Fe Institute: LLMs and Word Models, all’indirizzo https://aiguide.substack.com/).

Per molte fra le domande “difficili” che abbiamo menzionato, dunque, non esiste necessariamente una risposta univoca o condivisa. Cosa che rende, credo, ancor più importante e interessante esplorare con attenzione gli sviluppi di questo settore di ricerca.
Dal test di Turing a Odissea nello spazio: le attese deluse dell’Ia delle origini

Usciva in questi giorni 75 anni fa l’articolo del matematico inglese sul rapporto tra macchine computazionali e intelligenza, che divenne uno dei pilastri teorici per generazioni di scienziati al lavoro sull’intelligenza artificiale. La visione delle origini, basata sulla concezione logico linguistica dell’intelligenza, si rivelerà fallimentare. Ma sulle domande di fondo si discute oggi come allora
In questi giorni, settantacinque anni fa, una delle menti più brillanti del ventesimo secolo, il logico e matematico inglese Alan Turing, stava probabilmente dando gli ultimi tocchi a un articolo che continua a essere al centro di un acceso dibattito filosofico, e che costituisce uno dei pilastri teorici del lavoro sull’intelligenza artificiale. Intitolato Computing Machinery and Intelligence (Macchine computazionali e intelligenza), l’articolo – che tocca temi su cui Turing rifletteva già da diversi anni – sarebbe uscito su Mind, la più importante rivista filosofica inglese, nel numero dell’ottobre 1950. Si tratta di un testo abbastanza accessibile anche per un lettore non esperto: la traduzione italiana più recente, a cura e con un’utile nota critica di Diego Marconi, è stata da poco pubblicata in un agile libretto Einaudi di cui consiglio senz’altro la lettura (anche se il titolo italiano di questa edizione – Macchine calcolatrici e intelligenza – semplifica forse troppo il concetto di “computing machinery” come lo intendeva Turing).
Turing morirà, quasi sicuramente suicida, quattro anni dopo, depresso per le conseguenze fisiche e psicologiche del barbaro trattamento a base di estrogeni al quale era stato condannato per “curarne” l’omosessualità: condanna oggi fortunatamente impensabile, e che continua a pesare come un macigno sull’immagine storica del sistema giudiziario inglese. Due anni dopo la morte di Turing, nel 1956, un giovane e promettente matematico del Dartmouth College, John McCarthy, ospiterà presso il suo dipartimento un seminario estivo di ricerca basato su un documento di dodici pagine scritto nel 1955: il documento contiene la prima occorrenza ufficiale dell’espressione “intelligenza artificiale”, e anche la prima mappatura delle varie linee di ricerca esistenti nel settore.
Cosa rimane oggi, di questo lavoro pionieristico? E come mai l’attenzione sull’intelligenza artificiale è esplosa solo pochi anni fa, se la storia dell’IA è così lunga? In realtà, come vedremo, l’intelligenza artificiale delle origini è molto diversa da quella di oggi. Ma alcune tematiche affrontate da quella generazione di studiosi restano centrali.

Quel qualcosa in più
Nel suo articolo, Turing parte da un interrogativo assai semplice: le macchine possono pensare? Per rispondere a questa domanda, dovremmo sapere cosa intendiamo per “macchina” e cosa intendiamo per "pensare”. Dal punto di vista di Turing, la prima domanda è più facile: aveva dedicato la vita a riflettere sul concetto di computazione e di macchina computazionale. Ma concetti come quelli di “pensiero”, “intelligenza” e simili sono molto più ostici: sembra quasi impossibile trovarne definizioni chiare e soddisfacenti. Turing propone allora di cambiare prospettiva: anziché interrogarsi su cosa siano pensiero e intelligenza, chiediamoci invece in quali situazioni siamo portati ad attribuire, a riconoscere pensiero e intelligenza. Concentriamoci insomma sui comportamenti intelligenti, più che sull’intelligenza in sé: chiediamoci quali siano, e se e quali di questi comportamenti potrebbero essere riprodotti da una macchina opportunamente addestrata. Una macchina capace di produrre autonomamente l’ampio spettro di comportamenti sulla cui base attribuiamo intelligenza a un essere umano dovrebbe essere considerata anch’essa intelligente: è questa la base del cosiddetto “test di Turing”.
Quella di Turing è una posizione molto concreta e operativa, che sembra evitare il terreno minato della pura speculazione teorica. Ha però una conseguenza che piace poco a chi non accetta criteri “comportamentisti” per l’intelligenza: il comportamento esteriore – obiettano infatti almeno alcuni fra i suoi critici – ci dice poco su quel che succede dentro la macchina. Nel parlare di intelligenza, normalmente diamo molta importanza anche a quelli che sembrano essere “stati interni” del processo di pensiero: comprensione, consapevolezza, coscienza, autocoscienza… Ma chi ci garantisce che una macchina che si comporta in maniera intelligente sia davvero intelligente? Chi ci garantisce che capisca quel che sta facendo?
Il filosofo John Searle è stato uno dei padri di queste obiezioni, che troviamo ancora, frequentissime, fra chi nega a priori che un sistema di IA come quelli odierni sia o possa diventare intelligente: se il comportamento intelligente non basta, e serve qualcosa in più, le sole capacità del sistema, per quanto sorprendenti, non sono in grado di garantire intelligenza. Ma la forza della posizione di Turing non va affatto sottovalutata: cos’è, esattamente, questo “qualcosa in più”? Come si manifesta, se non esiste un criterio che ci consenta di riconoscerlo? Il rischio di un dualismo in cui uno dei termini dell’equazione – si tratti di “comprensione”, "coscienza” o altro – risulta totalmente misterioso e inattingibile, è dietro l’angolo.
Oltre le visione logico simbolica
C’è invece un altro aspetto dell’intelligenza artificiale classica (quella che oggi viene chiamata anche GOFAI: Good Old-Fashioned Artificial Intelligence, la buona intelligenza artificiale dei tempi andati) che oggi sembra decisamente invecchiato. Tanto Turing quanto i partecipanti al seminario di Dartmouth avevano una concezione fondamentalmente logico-linguistica dell’intelligenza. Per loro, siamo intelligenti soprattutto per la nostra capacità di ragionare e di usare il linguaggio. Anche i comportamenti intelligenti ai quali fa riferimento il test di Turing erano comportamenti logico-linguistici: le capacità della macchina vengono infatti valutate attraverso uno scambio linguistico. Inoltre, si riteneva, alla base del ragionamento c’è la logica, e il linguaggio è in fondo una manipolazione di simboli che deve seguire delle regole: sono queste le capacità che si cerca di riprodurre nella macchina. L’IA classica è dunque innanzitutto logico-simbolica.
Alle spalle di questa concezione c’è una lunga tradizione filosofica: l’idea di Hobbes del linguaggio come calcolo, l’idea di Leibniz che sia possibile descrivere la realtà attraverso una lingua perfetta, basata sull’uso di numeri e su regole semplici ed esplicite… In sostanza, si riteneva possibile produrre macchine computazionali intelligenti perché si pensava che in qualche misura anche la nostra intelligenza fosse computazionale.
Sostenere questa tesi sembra oggi più difficile. Innanzitutto, perché siamo più attenti anche ad altre forme di intelligenza, legate a comportamenti non necessariamente logico-linguistici: intelligenza emotiva, intelligenza spaziale… Ma il grosso problema dell’IA logico simbolica è un altro: nonostante le enormi aspettative delle origini, questi sistemi non si sono avvicinati neanche lontanamente ai risultati promessi.
Nel 1950, Turing ipotizzava che avremmo visto le prime macchine capaci di superare il suo test entro una cinquantina di anni. Ancora nel 1967, lavorando come consulente per uno dei capolavori della cinematografia, il film 2001 Odissea nello spazio di Stanley Kubrick (che uscirà nelle sale nel 1968), un altro dei partecipanti all’incontro di Dartmouth, Marvin Minsky, considerava plausibile l’idea che all’inizio del nuovo millennio avremmo avuto macchine come HAL 9000, il computer (pericolosamente) intelligente su cui ruota una parte fondamentale del film. Pochi anni dopo, lo stesso Minsky riconoscerà, con grande onestà intellettuale e grande curiosità verso nuovi, possibili indirizzi di ricerca, che quell’aspettativa era andata delusa.
L’IA, per avere successo, doveva dunque cercare nuove strade. Quali? Proveremo ad esplorarle fra due settimane, nel prossimo articolo di questa serie.
Neuroni, segnali e probabilità: così il computer imitò il cervello
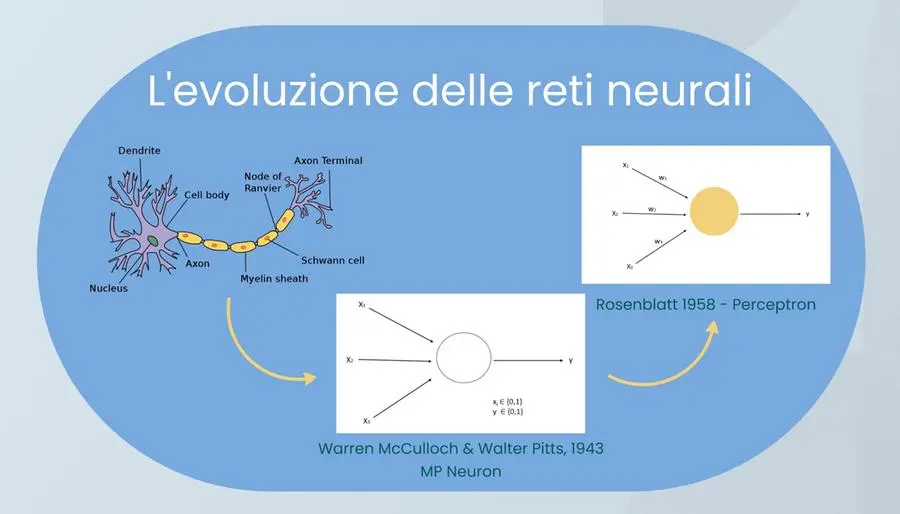
Le reti neurali rappresentano il cambio di paradigma che condurrà all’Ia di oggi. Dai segnali binari del modello MP a quelli “pesati” del percettrone di Rosenblatt, ecco la loro evoluzione nella storia
I primi ricercatori impegnati nel campo dell’intelligenza artificiale, fra il 1950 e l’inizio degli anni ’70, avevano lavorato usando metodi prevalentemente logico-simbolici. L’idea che li guidava era che la nostra intelligenza fosse legata in primo luogo alla capacità di ragionamento logico e all’uso del linguaggio, visto come un sistema di manipolazione di simboli attraverso regole. E dato che anche i computer funzionano usando regole e simboli, la costruzione di computer intelligenti sembrava a portata di mano.
Questa strada, però, ha portato risultati molto inferiori alle attese. I computer sanno fare calcoli, sanno manipolare simboli in base a regole. Ma se cerchiamo di riprodurre comportamenti intelligenti complessi, ad esempio la capacità di usare il linguaggio nella pluralità di situazioni e contesti propri dell’interazione linguistica umana, i programmi informatici tradizionali sembrano decisamente inadeguati.
Serviva una strada nuova, e questa strada fu trovata in un filone di ricerca che era già presente al tempo dell’intelligenza artificiale delle origini, ma che ha poi mostrato una capacità di evoluzione per molti versi sorprendente: le reti neurali.
La ricerca sui neuroni
Il lavoro sulle reti neurali era iniziato ancor prima che fossero disponibili i primi elaboratori elettronici: l’obiettivo iniziale non era infatti quello di costruire macchine intelligenti, ma quello di capire meglio come lavorava il nostro cervello, fornendo un modello semplificato del funzionamento dei neuroni che lo compongono. Può essere utile, a questo punto, fare un passo indietro. Nel 1873 Camillo Golgi, un medico italiano, aveva inventato un metodo geniale per visualizzare, al microscopio, le singole cellule del sistema nervoso e la loro struttura reticolare: la “reazione nera”, che permette di far risaltare, colorandole di nero, alcune cellule e le loro ramificazioni.
Quella di Golgi è una scoperta che si rivela ben presto importantissima; grazie alla possibilità di visualizzare queste strutture, un altro studioso di medicina, lo spagnolo Santiago Ramón y Cajal, formula alcuni anni dopo la “teoria del neurone”: l’idea che il funzionamento del cervello si basi su miliardi (oggi pensiamo fra 80 e 90 miliardi) di neuroni interconnessi. Per le loro scoperte, Golgi e Cajal vinceranno – insieme – il premio Nobel per la medicina nel 1906, lo stesso anno in cui Carducci vinse quello per la letteratura. Golgi e Carducci sono i primi due premi Nobel italiani, ma il nome di Carducci è molto più noto di quello di Golgi, che meriterebbe almeno la stessa fama.
Il modello logico
Nel 1943 un neurofisiologo, Warren McCulloch, e un logico, Walter Pitts, partono da queste scoperte per proporre un modello “logico” del funzionamento dei neuroni. La loro idea è che si possa spiegare il funzionamento del cervello pensando alla rete di neuroni come a una sorta di rete logica, in cui ogni neurone riceve più segnali in ingresso (da organi sensoriali o da altri neuroni) attraverso i dendriti: fibre che fungono da canali di input verso il corpo del neurone. Il neurone elabora questi segnali in base a proprie regole specifiche ed emette attraverso l’assone un segnale in uscita, a sua volta distribuito ad altri neuroni.
Nel modello di McCulloch e Pitts (il cosiddetto neurone MP, dai nomi dei due ricercatori), sia i segnali in ingresso sia quelli in uscita sono binari (“0” o “1”), e il neurone diventa dunque una sorta di minuscolo circuito logico. L’articolo scritto da McCulloch e Pitts, Un calcolo logico delle idee immanente nell’attività nervosa, mostrava fin dal titolo il forte debito con l’idea che il nostro cervello fosse in fondo basato sull’uso della logica.
Un nuovo modello
Come è facile capire, questo modello andava benissimo ai pionieri dell’intelligenza artificiale logico-simbolica: nel documento preparatorio dell’incontro di Dartmouth del 1956, lo stesso in cui compariva per la prima volta l’espressione intelligenza artificiale, viene citato come una delle strade che si sarebbero potute seguire nella costruzione di sistemi informatici intelligenti.
In che senso, allora, le reti neurali rappresentano un cambiamento di paradigma?
Per capirlo bisogna guardare alle evoluzioni successive di questa idea, che la allontanano parecchio dal “logicismo” iniziale. Nel percettrone, un’evoluzione del neurone MP proposta alla fine degli anni ’50 dallo psicologo sperimentale statunitense Frank Rosenblatt, si rinuncia all’idea che i segnali in ingresso debbano essere necessariamente binari (più tardi si farà lo stesso anche per i segnali in uscita), e si aggiunge un elemento nuovo, il “peso”. L’idea è che il neurone che riceve un segnale non si limiti ad acquisirlo passivamente, ma gli attribuisca invece un’importanza – rappresentata a sua volta da un parametro numerico, il peso (“w”, dall’inglese weight) – maggiore o minore, a seconda dei propri scopi.
Così, ad esempio, i neuroni impegnati quando attraversiamo una strada daranno probabilmente poca importanza, e dunque un peso basso, al cinguettio di un uccello in lontananza, mentre daranno un’importanza decisamente maggiore, e dunque un peso alto, ai segnali visivi che ci informano della presenza di un’auto che si avvicina a gran velocità. Il segnale emesso dal neurone dipenderà allora dai valori (pesati) dei segnali in ingresso: se viene superato un determinato valore di soglia, il neurone si attiverà, altrimenti no.
Questo modello è più complicato del neurone MP, ma è ancora deterministico: se conosciamo valori, pesi e valore di soglia, possiamo prevedere esattamente come si comporterà ogni neurone della rete. Così, ad esempio, un neurone con valore di soglia 0,5 non si attiva mai se la sommatoria pesata degli input è 0,49, e si attiva sempre se è 0,51. Ma… non potrebbe essere più sensato, invece, pensare in termini probabilistici? Pensare, cioè, che l’aumento della sommatoria pesata degli input aumenti la probabilità di attivazione del neurone, senza presupporre un valore di soglia fisso?
La probabilità
Questa evoluzione avviene nel corso degli anni ’80. E il passaggio da neuroni deterministici a neuroni probabilistici, associato alla costruzione di reti sempre più complesse, che comprendono molti strati di neuroni fra l’input e l’output, cambia tutto. Le reti neurali diventano più flessibili: oltre ai pesi e ai valori possiamo sperimentare funzioni (probabilistiche) di attivazione diverse, cercando quelle che funzionano meglio in una determinata situazione.
Inoltre, l’aumento degli strati della rete permette di creare algoritmi che modificano “all’indietro” i parametri, premiando con valori e pesi man mano più alti i neuroni che intervengono in decisioni corrette e “punendo” con valori e pesi più bassi quelli che intervengono in decisioni sbagliate. Tuttavia, in questo modo le reti neurali diventano anche più opache: non sappiamo più prevedere con esattezza neanche il comportamento di un singolo neurone, figuriamoci di una rete che ne comprende decine o centinaia di migliaia.
I sostenitori della “Good, Old-Fashioned Artificial Intelligence”, la buona vecchia intelligenza artificiale logico-simbolica delle origini, avrebbero probabilmente guardato con una certa diffidenza a queste enormi reti fatte di numeri (valori, pesi…) che cambiano continuamente man mano che la rete viene addestrata, e che si comportano in maniera sempre in parte imprevedibile. Dov’è la logica? Dov’è il linguaggio?
Eppure, nel costruire sistemi intelligenti queste reti sembrano funzionare molto meglio della vecchia IA logico-simbolica. E, come vedremo nel prossimo articolo di questa serie, è attraverso queste reti che siamo arrivati all’intelligenza artificiale generativa di oggi.
Molecole di gas e foto di gattini, il viaggio dell’Ia dal percettrone a ChatGpt

La ricerca sull’intelligenza artificiale conosce una drammatica battuta di arresto nel 1969 quando un volumetto dimostra che le reti neurali non erano in grado di risolvere semplici problemi logici. Poi la svolta con l’avvento delle reti neurali “profonde”, con diversi strati di neuroni fra l’input e l’output. Trent’anni di tentativi fino alla metà degli anni ‘10
Le reti neurali nascono dall’idea di cercare un modello semplificato del funzionamento del nostro cervello. I ricercatori che, intorno alla metà del secolo scorso, hanno avviato questo lavoro pensavano che il nostro cervello fosse in sostanza un sofisticato strumento di riconoscimento e manipolazione di simboli.
La neurobiologia suggeriva che il cervello fosse composto soprattutto da neuroni, cellule capaci di ricevere informazioni attraverso più canali in ingresso, di elaborarle, e di restituire un output attraverso i propri canali in uscita.
L’intelligenza umana poteva essere il risultato dell’interazione dei miliardi di neuroni di cui disponiamo, collegati fra loro in reti complesse? Ed era possibile costruire un modello che riproducesse queste strutture?
Neuroni deterministici
I primi modelli di questo tipo si basavano su neuroni (simulati) deterministici: un neurone riceve segnali di input, rappresentati nel modello attraverso valori numerici, che possono essere “pesati” in funzione della maggiore o minore importanza che il neurone “ricevente” attribuisce loro. Il neurone mette insieme i valori pesati che ha ricevuto, e valuta se superano o no un determinato livello di soglia. Se il livello di soglia è superato, il neurone si attiva. Altrimenti, no.
Già le prime reti di questo tipo – come quelle realizzate alla fine degli anni ’50 da Frank Rosenblatt, psicologo sperimentale statunitense, usando un simulatore di neuroni battezzato “percettrone” – mostravano capacità di apprendimento e riconoscimento delle forme.
E lo stesso Rosenblatt aveva sottolineato un motivo d’interesse delle reti neurali: lavorare su simulatori di neuroni è un metodo più “concreto” e vicino al funzionamento del cervello biologico di quanto non sia lavorare esclusivamente attraverso strumenti di programmazione tradizionale. Su YouTube (l’indirizzo è https://youtu.be/cNxadbrN_aI) potete vedere, in un breve filmato d’epoca, uno di questi simulatori al lavoro, impegnato nel curioso compito di distinguere immagini di volti maschili da immagini di volti femminili.
Un compito che oggi considereremmo probabilmente legato a pregiudizi di genere nella costruzione di rappresentazioni “modello”: e infatti il sistema entrava in crisi davanti alle immagini di capelloni, di giudici con la parrucca o di acconciature non standard.
Un clamoroso fallimento
Pur se basate sulla manipolazione di simboli attraverso modelli che a livello di singolo neurone sono deterministici, dunque, le reti neurali proposte da Rosenblatt mostravano in qualche misura una strada nuova rispetto all’intelligenza artificiale logico-simbolica tradizionale. Nel 1969, però, arrivò un risultato inatteso e scoraggiante, dovuto a Marvin Minsky, che all’epoca era uno dei padri dell’intelligenza artificiale logico-simbolica e che in seguito ne riconoscerà il sostanziale fallimento, e a Seymour Papert, informatico e pedagogista sudafricano che sarà fra i padri della robotica educativa.
In un volumetto intitolato Perceptron, Minsky e Papert sembrano dimostrare che i percettroni non possono simulare alcune operazioni logiche piuttosto semplici, come l’ “o” esclusivo, o “XOR” (vero se e solo se esattamente uno dei disgiunti è vero, e falso se sono tutti e due falsi o tutti e due veri). Non entrerò qui nei dettagli di questa dimostrazione: quel che ci interessa in questa sede è che sembra infliggere un colpo durissimo alle reti neurali.
Se non sono in grado di usare un operatore logico così semplice, come possiamo pensare di usarle per costruire sistemi intelligenti?
In realtà, il risultato di Minsky e Papert è parziale: si riferisce solo alle reti che hanno un singolo strato di percettroni fra l’input e l’output. Ma le reti su cui si lavorava all’epoca erano di questo tipo, e per diversi anni l’idea delle reti neurali sembra condannata all’irrilevanza. Il lavoro in questo campo non sarà mai veramente interrotto, ma fino a verso la metà degli anni ’80 rappresenterà, nel mondo dell’intelligenza artificiale, una nicchia minoritaria.
Molecole di gas e gattini
Progressivamente, però, proprio nel corso degli anni ’80 la situazione cambia.
Si comincia a lavorare sulle reti neurali “profonde”, con diversi strati di neuroni fra l’input e l’output, che permettono di muovere molto più liberamente informazione all’interno della rete e di aggiustare man mano pesi e valori.
Per l’attivazione dei neuroni cominciano a venire utilizzate, al posto dei valori di soglia deterministici, funzioni probabilistiche. E le nuove reti neurali profonde mostrano capacità sempre maggiori.
Uno dei padri di questi sviluppi è Geoffrey Hinton, informatico anglo-canadese che nel 2024 riceverà il premio Nobel per la fisica. Hinton parte dalla meccanica statistica di Boltzmann, in cui le molecole di un gas si muovono in maniera inizialmente disordinata per trovare man mano una configurazione più stabile, quella che richiede meno energia.
E immagina che una rete neurale si comporti un po’ nello stesso modo: i neuroni, collegati fra loro da legami più o meno forti (che corrispondono ai pesi), si attivano e disattivano in maniera inizialmente casuale ma progressivamente più ordinata, man mano che “imparano” a rappresentare efficacemente i dati ai quali sono state esposte.
E imparando a riconoscere strutture nei dati, queste reti diventano capaci non solo di discriminare casi diversi – ad esempio, di classificare correttamente l’immagine di un gatto o di un cane, dopo aver visto molte immagini etichettate di gatti e di cani – ma anche di produrre dati nuovi che “imitino” caratteristiche dei dati su cui sono state addestrate. Possiamo dunque chiedere alla rete, nel nostro esempio, di generare nuove immagini di un gatto o di un cane: immagini diverse da quelle su cui è stata addestrata, ma sufficientemente “simili” a quelle immagini da permetterne il riconoscimento. In altre parole, il processo di apprendimento a cui sono sottoposte queste reti non produce solo capacità discriminative, ma anche capacità generative.
Verso il salto decisivo
Si tratta di un passo decisivo verso l’intelligenza artificiale generativa di oggi. Ma, per arrivarci, servono dei risultati ulteriori: le reti immaginate inizialmente da Hinton – che proprio per il paragone con la meccanica statistica di Boltzmann erano chiamate Boltzmann Machines – non erano infatti prive di problemi: dovendo “provare” molte configurazioni di neuroni accesi e spenti prima di trovare uno stato stabile (“a bassa energia”), richiedevano risorse di computazione assai alte, che crescevano esponenzialmente all’aumento di complessità della rete stessa.
E non c’erano garanzie né sul tempo richiesto per trovare stati a bassa energia, né che gli stati trovati fossero effettivamente quelli ottimali e non solo un “minimo” locale in cui la rete poteva adagiarsi senza trovare le soluzioni effettivamente migliori.
Per una trentina di anni, dunque, fra la metà degli anni ’80 del secolo scorso e la metà degli anni ’10 di questo secolo, la storia delle reti neurali è fatta di continue esplorazioni di architetture diverse e più efficienti.
Fino a quando, nel 2017, un gruppo di ingegneri di Google propone quella che sembra solo una nuova architettura fra tante, e che si rivela invece straordinariamente potente: i modelli basati su Transformer, che saranno alla base di ChatGPT e di moltissimi fra i nuovi sistemi di intelligenza artificiale generativa.
Nel prossimo e ultimo articolo di questa serie esamineremo questo sviluppo, che porta alla rapidissima evoluzione degli ultimi anni, e alle molte domande che questa evoluzione ci pone.
LEZIONI DI INTELLIGENZA ARTIFICIALE – 5
Per produrre testo serve attenzione, l’intuizione rivoluzionaria di OpenAI

Nel 2017 un articolo di un gruppo di ricercatori di Google pone il problema delle reti neurali in termini di attenzione. Un concetto decisivo. Una giovane azienda si accorge subito delle potenzialità di questo approccio. Così nasce ChatGPT, la “nuova” intelligenza artificiale generativa. I grandi modelli linguistici imparano a produrre linguaggio. Quella che leggete è l’ultima puntata delle lezioni di intelligenza artificiale del professor Gino Roncaglia (almeno per ora)
Come funzionano i sistemi attuali di intelligenza artificiale generativa? Molto nasce da un articolo rivoluzionario pubblicato nel 2017 da un gruppo di ricercatori di Google, intitolato Attention Is All You Need (Tutto quel che ti serve è l’attenzione). Ma di quale attenzione si tratta?
Le prime reti neurali capaci di produrre linguaggio avevano limiti enormi nel “ricordare” sia l’input ricevuto (il prompt), sia il testo che veniva man mano generato. Per avere un’idea della situazione nella quale si trovava chi programmava reti di questo tipo prima del 2017, potete pensare al gioco del “cadavere squisito”, popolare fra i surrealisti francesi del secolo scorso. Le persone che partecipavano al gioco dovevano collaborare nello scrivere una poesia o un racconto, alternandosi nella scrittura. C’era però un vincolo non banale: a ogni turno, chi doveva scrivere poteva vedere solo l’ultima parola usata da chi l’aveva preceduto. Come è facile capire, questo produceva testi assai sconclusionati, in cui – anche se il “raccordo” fornito dall’ultima parola di ogni segmento garantiva un minimo di continuità al testo – mancava completamente un filo narrativo o compositivo.
Long short-term memory
Prima dell’articolo del 2017, le reti neurali erano un po’ nella stessa situazione: man mano che il testo veniva generato, il sistema “dimenticava” le parti più lontane, e perdeva il filo della scrittura. Un primo tentativo per superare questo problema era stato fatto nel 1997 dagli informatici tedeschi Sepp Hochreiter e Jürgen Schmidhuber con la Long Short-Term Memory (LSTM).
L’idea era quella di includere nella rete una sorta di memoria tampone (piuttosto ampia e capace di gestire anche alcune dipendenze “lontane”: da qui la curiosa denominazione long short-term memory) per conservare le informazioni. Le celle di questa memoria venivano gestite da circuiti capaci di conservarvi e di richiamare informazioni (attraverso porte di ingresso e di uscita), ma anche di dimenticare le informazioni poco usate, attraverso una particolare porta denominata “forget” gate: la porta che dimentica.
Il problema dell’attenzione
La possibilità di dimenticare, associata a una “finestra” di memoria più ampia, migliorava un po’ la situazione, ma la finestra disponibile non era comunque ampia abbastanza da coprire un testo più lungo di poche frasi. Soprattutto, restava irrisolto un problema enorme: per costruire testi funzionanti, non basta la memoria; serve anche la capacità di riconoscere e di gestire i rapporti di dipendenza, i riferimenti, le parole o i concetti lasciati impliciti.
Per capirlo, ripensate a quel che avete letto finora in questo articolo. In apertura, viene citato il lavoro del 2017 sull’attenzione, e viene posta la domanda «di quale attenzione si tratta?». Una lettrice o un lettore umano prosegue la lettura tenendo sempre implicitamente presente quella domanda, e si aspetta che il seguito dell’articolo ponga le basi per dare una risposta. Capisce di dover dedicare particolare attenzione… al tema dell’attenzione. Arrivati a questo punto, quella frase è abbastanza lontana nel testo, ma – anche se non ve ne rendete pienamente conto – continuate a tenerla presente. E anche io che scrivo continuo a tenerla presente, perché so che devo fornire una risposta. In altre parole, in un testo ci sono sempre frasi, parole, concetti ai quali, man mano che procede la lettura (e la scrittura), serve dedicare più attenzione rispetto ad altri. Non basta una memoria, serve una memoria diversificata, che ricordi non solo la successione di parole ma anche quanto sono importanti e che relazioni hanno fra loro. E questa valutazione deve essere aggiornata continuamente.
Il meccanismo dell’attenzione – inserito in un’architettura particolare, denominata “transformer” – serve proprio a questo: permette a una rete di focalizzarsi sulle parti rilevanti di una sequenza man mano che elabora i dati, dedicando un’attenzione diversa – e dinamica – a elementi diversi della sequenza esaminata.
La nascita di ChatGPT
Questa idea ha mostrato subito le sue enormi potenzialità nel campo della traduzione automatica (dove una primissima versione dell’idea di attenzione era stata sperimentata già nel 2014): con l’attenzione, una rete di traduzione poteva “guardare” direttamente le parole più rilevanti della frase di partenza mentre generava ciascuna parola nella frase di arrivo, un po’ come un traduttore umano che si concentra su una porzione alla volta del testo originale.
Quando nel 2017 esce l’articolo dei ricercatori di Google, c’è una giovane azienda che si accorge subito delle potenzialità dei transformer e del meccanismo dell’attenzione: si tratta di OpenAI, che era nata nel dicembre 2015 e lavorava proprio su intelligenza artificiale e reti neurali.
Se chiedete quando sia nata la “nuova” IA generativa, probabilmente molti vi risponderanno che è nata a fine 2022, quando Open AI lancia ChatGPT: un chatbot, cioè una piattaforma attraverso cui chattare, e dunque dialogare, con un sistema di intelligenza artificiale capace di usare il linguaggio. In realtà, Open AI aveva prodotto una prima versione di GPT già nel 2018 (la sigla GPT vuol dire Generative Pre-trained Transformer: un sistema generativo, pre-addestrato e basato sull’architettura dei transformer e dunque sul meccanismo dell’attenzione). E già nel 2019 era possibile dialogare on-line con la seconda versione di GPT, attraverso un sito chiamato “Talk To Transformer”. Ma all’inizio se ne accorgono in pochi: perché le straordinarie (e in parte inquietanti) capacità dell’IA generativa ricevano l’attenzione che meritano bisogna aspettare altri tre anni, fino – appunto – all’uscita del sito ufficiale di ChatGPT.
Prosecuzioni ragionevoli
ChatGPT e gli altri sistemi analoghi sono grandi modelli linguistici basati sulla predizione di token: sulla base di uno sterminato corpus di testi si costruiscono, in mesi e mesi di addestramento, modelli numerici di migliaia di “dimensioni d’uso” delle parole di moltissime lingue diverse. In questi modelli ogni parola, o “token”, viene rappresentata attraverso (migliaia di) numeri. In questa rappresentazione, “elefante” e “zanzara” avranno alcune dimensioni numericamente abbastanza vicine (sono tutti e due animali, hanno zampe…) e altre assai diverse (la zanzara è più piccola dell’elefante, è più antipatica, ha una vita più breve, punge…). Il sistema progressivamente capisce che, ad esempio, la frase «stamattina mi ha punto una terribile…» potrebbe proseguire con «zanzara» ma non con «elefante». Impara a predire prosecuzioni ragionevoli. E quando io chiedo, ad esempio, «cosa potrei fare di bello domani?» capisce che una buona prosecuzione potrebbe cominciare con «domani». Poi, un token alla volta, prosegue, ogni volta «riguardando» la domanda e quanto prodotto fino a quel momento, ogni volta «aggiustando» l’attenzione: il risultato sarà, ad esempio, «domani potresti fare una gita».
La straordinaria capacità di questo meccanismo nella produzione di testi sintatticamente e semanticamente coerenti ha sorpreso anche chi li ha creati: non ci si aspettava che funzionassero così bene. Contemporaneamente, meccanismi in parte analoghi (e in parte diversi) hanno permesso di costruire sistemi che generano immagini, audio, video… e anche sistemi “multimodali”, che possono generare, ad esempio, un video con audio e sottotitoli.
L’intelligenza artificiale generativa è ancora giovanissima, e sta già cambiando il mondo in cui viviamo. Nella serie di articoli che si conclude oggi ho cercato di raccontarne le origini e i concetti fondamentali. Seguirne gli sviluppi, capire come gestirne le potenzialità e i rischi, sono fra le priorità fondamentali a cui tutti noi dovremo dedicare attenzione (la nostra attenzione, e non solo quella delle reti neurali) nei prossimi anni.


Commenti
Posta un commento